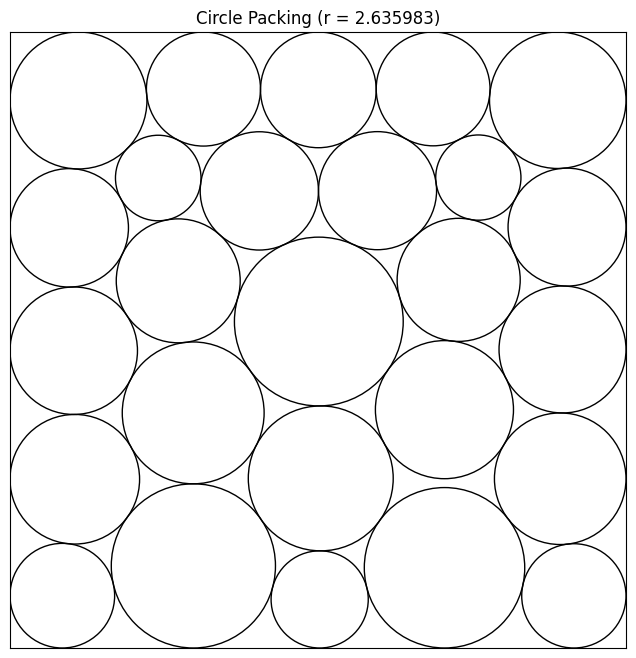
[Draft] Circle Packing with AlphaEvolve
I’m doing these projects to build my skills as an AI Research Engineer and communicator. Here’s what I learnt this time:
- Parallelism: Ray Core actors and tasks
- Containers: Docker images, Google Container Registry
- Cloud compute: Google Cloud Run
- LLMs: advanced prompt engineering, agentic AI
- Data analysis: textual database management, evolutionary island dashboard

Introduction ¶
A couple months ago, GDM released AlphaEvolve, an exciting update on LLM-driven code generation using evolutionary methods. In their paper, they showed that repeatedly querying an LLM with progressively richer prompts, constructed by providing feedback on previous attempts, can result in superhuman problem solving.
Notably, they used AlphaEvolve to improve Google’s data center scheduling efficiency by 0.7%, reduce Gemini’s training time by 1%, optimise a TPU design, and speed up a FlashAttention kernel by 32%. They also found SOTA solutions for a range of mathematical problems, spanning Analysis, Geometry, and Combinatorics.
There already exists an open-source replication called OpenEvolve, but they weren’t able to fully replicate the circle-packing result, requiring some manual prompting and a two-stage process to attain 99.94% of the AlphaEvolve result. This is how I managed to beat it!
Implementation ¶
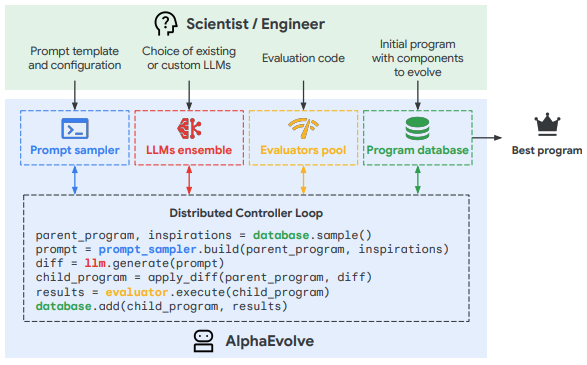
AlphaEvolve consists of 4 components: a program database, a prompt builder, an LLM ensemble, and an evaluator pool. They form an evolutionary loop that increases program quality over time by repeating these 6 steps:
- The database sample returns a parent program and some inspiration programs
- A prompt is built using these programs to request a diff
- An LLM is used to generate the diff
- The diff is applied to the parent program to generate a child program
- The child program is passed to an evaluator to get scores
- The combined program and scores are stored back in the program database
The pipeline’s throughput can be increased by running these steps in parallel for multiple different parent/inspiration samples. I used Ray to handle the parallelism.
def run_pipeline(
parent: Program,
inspirations: list[Program],
cfg: PipelineConfig,
api_key: str,
) -> Program | Exception:
try:
prompt = build_prompt(parent, inspirations, cfg.prompt_builder_cfg)
diff, reasoning = generate_diff_and_reasoning(prompt, api_key, cfg.llm_cfg)
child_content = apply_diff(parent.content, diff)
scores, artifacts = evaluate_program(child_content, cfg.program_evaluator_cfg)
child = Program(
id=None,
island_id=parent.island_id,
generation=parent.generation + 1,
content=child_content,
parent_id=parent.id,
inspired_by_ids=[insp.id for insp in inspirations if insp.id is not None],
prompt=prompt,
reasoning=reasoning,
diff=diff,
scores=scores,
artifacts=artifacts,
)
return child
except Exception as e:
return e
@ray.remote
def run_pipeline_task(
parent: Program, inspirations: list[Program], cfg: PipelineConfig, api_key: str
) -> Program | Exception:
return run_pipeline(parent, inspirations, cfg, api_key)
Database sampling ¶
I divided the programs database into separate islands which grew their own evolutionary trees in isolation. Sampling an island returned the highest-scoring program as the parent, and I also sampled the next 3 best programs, the most recently generated program, and a random program as inspirations. This was a fairly deterministic process, so I limited the nubmer of parallel tasks per island to 2 in order to avoid excess redundancy from repeatedly sampling the same set of programs.
For every 20 programs generated on an island, the best program would be shared with its neighbouring islands, maintaining a balance between diversity through isolation and performance from collaboration.
for island_id, island in enumerate(self.islands):
if len(self.island_tasks[island_id]) >= island.cfg.max_parallel_tasks:
# Skip this island if it has reached the max number of running tasks
continue
parent, inspirations = island.sample()
task = run_pipeline_task.remote(
parent,
inspirations,
self.cfg.pipeline_cfg,
self.api_key,
)
task_id = id(task)
self.island_tasks[island_id][task_id] = task
logger.info(f"Started task {task_id} on island {island_id}.")
This wasn’t a particularly sophisticated setup, so I was surprised it worked so well. Future improvements could include score-weighted probabilistic sampling and a MAP-elites style algorithm, requiring a richer feature dictionary.
Prompt building ¶
Each prompt consists of several parts:
- Preamble: a high-level description of the AlphaEvolve process
- Task: a specific description of the problem to be solved, e.g. circle packing
- Parent: a multi-part section consisting of the parent code and its associated reasoning and scores
- Inspirations: similar to the parent section but for several inspiration programs
- Variation: a randomly sampled prompt variation, e.g. encouraging this diff to refactor the parent program without changing core functionality, or to write a completely new program from scratch
- Epilogue: a description of the specific format expected from the output
<PREAMBLE>
Act as an expert Python developer. Your job is to make iterative improvements to a source file in order to score highly on a task. You will be provided with a task description, a parent program, and a set of inspiration programs, which are previous attempts at solving the task. Your output will be a diff that will be applied to the parent program to create a new program.
</PREAMBLE>
<TASK>
You are an expert mathematician specializing in circle packing problems and computational geometry. Your task is to improve a constructor function that produces a specific arrangement of 26 circles in a unit square, such that none of them overlap. The function `pack_26()` should return a numpy array with 26 (x, y, r) rows, where (x, y) is the center of a circle and r is its radius. The score will be the sum of the radii of all circles, which you should maximise. Invalid packings, where circles overlap or extend beyond the unit square, will score 0. Functions which take more than 600 seconds to run will time out and score 0. The code for checking overlaps and bounds works with a numerical tolerance of 1e-9. This is a difficult problem so hard-coded solutions will not work well. The current best score found by other researchers is 2.635. The Python environment has the following libraries available: numpy, scipy.
</TASK>
<PARENT>
...
</PARENT>
<PARENT_REASONING>
* The previous attempts have not yielded any valid packing. This suggests that a complete rewrite is necessary.
* This new approach attempts to place circles in a structured, grid-like manner, which is a common strategy for circle packing.
* It starts with a central large circle and then tries to pack smaller circles around it and in the remaining space.
* The use of a `while` loop and `np.random.rand` suggests an iterative approach, potentially allowing for some randomized exploration of the packing space.
* The `is_valid` function (though not fully implemented in this snippet) indicates an intention to check for overlaps and bounds, which is crucial for a valid packing.
* The current `pack_26` implementation is a placeholder, and the goal is to provide a more sophisticated strategy.
</PARENT_REASONING>
<PARENT_SCORES>
{'INVALID_CODE_CHECK': 1.0, 'TIMEOUT_CHECK': 1.0, 'INVALID_TYPE_CHECK': 1.0, 'INVALID_LENGTH_CHECK': 1.0, 'INVALID_CIRCLE_CHECK': 1.0, 'OUT_OF_BOUNDS_CHECK': 1.0, 'OVERLAP_CHECK': 1.0, 'VALID_CHECK': 1.0, 'SCORE': 0.9674398198089572}
</PARENT_SCORES>
<INSPIRATION_57>
...
</INSPIRATION_57>
<INSPIRATION_57_REASONING>
...
</INSPIRATION_57_REASONING>
<INSPIRATION_57_SCORES>
...
</INSPIRATION_57_SCORES>
<INSPIRATION_51>
...
</INSPIRATION_51>
<INSPIRATION_51_REASONING>
...
</INSPIRATION_51_REASONING>
<INSPIRATION_51_SCORES>
...
</INSPIRATION_51_SCORES>
<VARIATION>
Try to tweak the parameters used in the previous completions to improve the score. This might include changing weights, adjusting learning rates, or modifying other hyperparameters. The goal is to find a better configuration that leads to a higher score without changing the overall approach or algorithm significantly.
</VARIATION>
<EPILOGUE>
Your output should consist of two parts: your reasoning for the changes and the diff itself. The reasoning should be a concise bullet-point list of the reasons why you believe the diff will improve the program's score. The diff should consist of SEARCH/REPLACE blocks that can be applied to the parent, and no other text. One diff may contain multiple SEARCH/REPLACE blocks, separated by newlines. The resulting program should be a valid Python program that will attempt to solve the task. It is important that the diff and code are valid, as invalid outputs will waste resources and time. Your response is limited to a maximum of 8192 tokens, so your changes must be small and focused.
SEARCH/REPLACE block rules:
1. Each SEARCH/REPLACE block consists of a SEARCH section and a REPLACE section
2. The SEARCH section begins with `<<<<<<<< SEARCH`, the REPLACE section begins with `========`, and the end of the block is marked with `>>>>>>>> REPLACE`.
3. The SEARCH section contains the code to be replaced, which should be uniquely identifiable within the parent program.
4. The REPLACE section contains the code that should replace the SEARCH code.
5. Both sections operate on a line-by-line basis.
6. A special case is when the SEARCH section is an empty line, which means the entire parent program should be replaced with the REPLACE section.
Example #1:
<PARENT>
def main():
print("Hello, world!")
</PARENT>
<DIFF>
<<<<<<<< SEARCH
print("Hello, world!")
========
print("Aloha, world!")
>>>>>>>> REPLACE
</DIFF>
Example #2:
<PARENT>
def main():
print("Hello, world!")
</PARENT>
<DIFF>
<<<<<<<< SEARCH
========
if __name__ == "__main__":
print("Aloha, world!")
>>>>>>>> REPLACE
Your output should be formatted as follows:
<REASONING>{reasoning}</REASONING>
<DIFF>{diff}</DIFF>
</EPILOGUE>
Diff generation ¶
This was the easy part, simply sending the assembled prompt to OpenRouter’s API. The setup was all in the prompt engineering, especially the epilogue, shown above, which requested bullet-point reasoning and a SEARCH/REPLACE diff format.
Program evaluation ¶
In order to safeguard against malicious code, I used Docker containers to evaluate the programs. An evaluation script eval.py was setup to receive programs as environment variables and print out a dictionary of scores to stdout. It could also output artifacts, such as error messages and circle packings, inspired by OpenEvolve.
FROM python:3.11-slim
RUN useradd -m sandboxuser
USER sandboxuser
WORKDIR /home/sandboxuser
RUN pip install --no-cache-dir numpy scipy
COPY eval.py .
ENTRYPOINT ["python", "eval.py"]
These containers could be run in parallel, either locally or on Google Cloud, allowing for distributed scaling.
Results ¶